 Iljoong's Blog
Iljoong's BlogDeveloping AI Application
이전 블로그에서 AI on Azure를 통해 AI에 대한 전반적인 소개를 했는데 이번 블로그에서는 AI 기반 애플리케이션 또는 서비스를 개발하는 방법에 대해서 소개하겠습니다.
AI App Overview
너무 간단하지 않으며 이해하기 쉬운 AI 애플리케이션으로 Facebook에서 제공하는 face tagging과 유사한 서비스를 개발하는 방법에 대해서 설명하겠습니다. 참고로, Face tagging은 그림과 같이 자동으로 사람을 얼굴을 인식(5명의 유명인사)하여 자동으로 태깅 및 수동으로 편집해주는 간단한 포토 서비스입니다.
(Click to watch video)
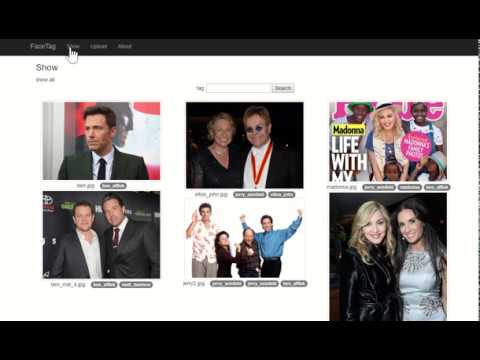
AI 애플리케이션 개발방법은 소개하기 전에 먼저 사람의 얼굴을 인식하는 방법에 대해서 간략하게 설명합니다.
Face detection
2000년대 이전까지 만해도 얼굴 인식은, 특히 실시간 얼굴 인식,은 어려운 기술이었으나 Viola와 Jones에 의해서 실시간 인식 알고리즘이 개발된 후 지금은 대부분의 디지털 카메라에서 흔하게 접하는 기술입니다.
Haar-cascade detection이 가장 기본적인 구현 방법이고, 좀더 개선된 histogram-of-oriented-gradient (HOG) based object detectors와 최근 Deep Learning 기반의 CNN/Faster-RCNN based detector 구현 방법들이 알려져 있습니다. 이 구현 방법들은 대표적인 이미지 라이브러리인 OpenCV와 Dlib에서 기본으로 제공하기 때문에 직접 알고리즘을 구현할 필요는 없습니다.
D2v2 VM에서 실행한 각 구현 방법의 성능은 아래의 테스트 결과를 확인하시고, 테스트 소스는 본 링크를 참조하시기 바랍니다.

간략하게 장단점을 설명하면 Haar-cascasde detection 방식이 인식 속도가 가장 빨라 일반적인 PC 환경에서도 실시간 인식이 가능하지만, 정면 얼굴이 아닌 경우 인식율이 많이 떨어지고 오탐(False Positive)도 종종 발생하는 단점이 있습니다. HOG 와 CNN 방식은 높은 인식율이 장점이긴 하지만 인식 속도 느려서 실시간 인식이 어렵고 GPU와 같은 Special HW가 요구됩니다.
참고로, Haar-cascasde detection은 Eye detection을 추가하면 처리 속도는 좀 늘어나지만 오탐은 많이 줄어 듭니다. 본 애플리케이션에서는 Harr-casacade Face + Eye detection 방식을 사용하며, 얼굴을 모두 인식하지는 못합니다.
Facial Recognition/Classification
얼굴 식별은 잘 알려진 Multi-class classification 방식을 기본으로 사용합니다. 좀더 정확한 식별을 위해서 Deep Learning 알고리즘 중 상대적으로 빠르고 이미지 식별에 뛰어난 VGG16 또는 Resnet50 모델을 사용합니다. 식별된 class(얼굴)를 기반으로 자동 태깅을 수행하기 위해서는 먼저, 태깅/식별 학습에 사용될 데이터셋을 준비해야 합니다.
Training Dataset
얼굴 태깅/식별을 위해 데이터셋을 별도로 준비하거나 준비가 어려운 경우 샘플 데이터셋으로 Kaggle에 공개된 5 Celebrity Face Dataset을 사용합니다. 이 데이터셋은 5명의 유명인사 ben_afflek, elton_john, jerry_seinfeld, madonna, mindy_kaling이 포함되어 있습니다.
가족의 얼굴을 태깅해보는 것도 좋은 방법입니다. 가족사진으로 데이터셋을 준비할 경우 사진에서 얼굴만 이미지를 추출하는 것이 귀찮을 수 있는데, 이때 Facecrop 스크립트을 사용할 수 있습니다.
Training DL Model
학습을 위한 전체 모델 및 검증은 Kaggle에 이전에 공개한 Kernel을 참조하십시오. 이 모델은 VGG16 또는 Resnet50 모델 사용하며, Transfer learning을 이용하여 빠르고 정확한 학습이 가능하고 Data augmentation을 사용하여 적은 샘플로 높은 Accuracy를 달성할 수 있습니다. 실 데이터에서도 생각보다 높은 식별율을 보여주지만 학습된 얼굴이 아닌 경우 5명 중에 가장 높은 확율의 얼굴로 인식됩니다. 새로운 얼굴 및 좀더 정확한 식별을 위해서는 신규 데이터셋의 지속적인 학습이 요구됩니다.
Building Application
많은 AI 관련 자료들은 이론 또는 모델링 툴에 대해서만 주로 다루는 반면 애플리케이션 개발을 위한 설명은 찾기 어려웠습니다. 그래서, 사실 이 블로그를 작성하게 되었습니다. 좀 늦게 알게 되었지만, Keras blog에 REST API 개발을 소개하는 글이 있으니 이 것도 함께 참고하시기 바랍니다.
Architecture
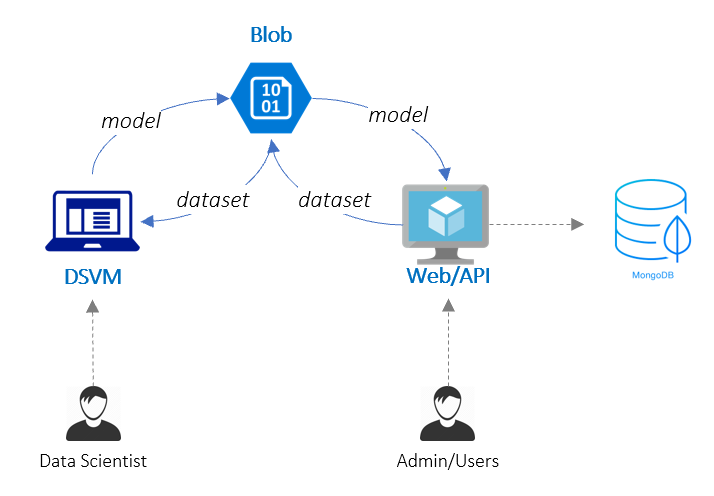
본 서비스는 기본적으로 Web/API App과 얼굴식별 정보 저장을 위한 DB로 구성됩니다. Web/API App은 먼저 간단하게 Python Flask 라이브러리를 이용했으며, DB는 SQL 보다는 json 형식의 데이터를 편리하게 처리할 수 있는 mongodb를 사용했습니다.
앞서 신규 데이터셋의 지속적인 학습이 요구된다고 했는데 AI App의 성공 여부는 결국 데이터 선순환을 통한 정확한 식별/예측입니다. 이를 위해서 아래와 같이 지속적인 학습 또는 Feedback Loop을 지원하는 구조로 개발되어야 합니다.

모델 파일 및 신규데이터 파일을 Blob 스토리지를 경우 시키는 이유는 모델/데이터 파일이 상대적으로 크기 때문에 좀더 효율적으로 사용(최신 파일만 VM에 유지)하기 위합니다. 참고로, Resnet50와 VGG16 모델 파일은 각각 약 400MB, 850MB 입니다.
추가적으로, 실제 엔터프라이즈 환경에서는 보안, 스케일 등을 추가 고려하여 아키텍처를 구성해야 합니다.
Use cases
주요 제공 기능은 다음과 같습니다.
- 갤러리 보기 (show): Responsive Web Design 스타일 웹사이트, 태그 표시, 페이징 및 태그로 검색
- 이미지 등록 (upload): 이미지 저장, 썸네일 저장, 얼굴 인식 및 자동 얼굴 식별/태깅
- 태그 수정 (edit): 태그 레이블 수정, 태그(자동 식별) 추가, 태그 삭제
- 테이터셋 수집: 특정 일자 이후의 얼굴 데이터셋 수집, zip 파일로 지정된 blob에 업로드
- 신규 데이터셋 수십은 REST API(/api/admin/job)로 호출
- blob에서 신규 데이터셋을 다운로드 받아 추가 학습 실행, 신규 모델을 blob에 업로드
- 모델 업데이트: 신규 모델을 다운로드 및 앱서비스에 적용
- 업데이트는 REST API(/api/admin/model)로 호출
Implementation
FaceTag 서비스의 얼굴식별에 사용되는 학습 모델을 로딩하는 코드 예입니다. 모델 대신 모델의 weight 파일을 사용할 수도 있습니다. 또한, 서비스가 다른 모델(예: 유명인사 얼굴, 가족 얼굴)도 사용할 수 있도록 모델 파일 위치, 모델 태그 정보를 환경변수로 입력 받습니다. 모델 파일이 없는 경우 얼굴 인식은 실행 되지 않습니다.
#appface.py
from keras.models import Model, load_model
def loadModel():
global labels
try:
modelpath = os.environ.get('MODELPATH')
logging.debug("modelpath = %s" % modelpath)
if (modelpath != None and modelpath != ""):
model = load_model(modelpath)
modeltags = os.environ.get('MODELTAGS', 'tag1;tag2;tag3;tag4;tag5;tag6;tag7;tag8;tag9;tag10')
logging.debug("modeltags = %s" % modeltags)
labels = modeltags.split(';')
else:
model = None
except Exception as e:
raise e
return model
모델의 predict 함수를 사용하여 사진 내의 얼굴 이미지로 얼굴을 식별합니다. 얼굴 이미지는 먼저 모델이 학습될 때 사용했던 이미지 사이즈로 변경해야 합니다. 한 가지 주의할 점은, predict 함수는 배치(여러 이미지)로 실행되기 때문에 하나의 이미지만 실행할 때 dimension을 확장해줘야 합니다. 또한, 학습때와 마찬가지로 이미지 값의 속성을 float으로 변경하고 255로 나누는 정규화 작업을 추가로 해줘야 합니다.
predict 함수의 결과 값은 모든 클래스의 확율이 리턴되므로 np.argmax 함수를 사용하여 가장 확율이 높은 클래스(위치)를 선택합니다. 이후, 클래스는 해당 태그 값으로 전환합니다.
#appface.py
def classifyFace(model, frame):
global labels
img = cv2.resize(frame, (img_size, img_size), interpolation = cv2.INTER_AREA)
x = np.expand_dims(img, axis=0)
x = x.astype(float)
x /= 255.
classes = model.predict(x)
result = np.squeeze(classes)
result_indices = np.argmax(result)
return labels[result_indices], result[result_indices]*100
가장 중요한 데이터 선순환을 위한 기능으로 신규 데이터셋을 수집하는 API와 새로운 모델을 다운로드 및 적용하는 API가 구현되었습니다.
#main.py
@app.route('/api/admin/job', methods=['POST'])
def runjob():
@app.route('/api/admin/model', methods=['PUT'])
def updatemodel():
자세한 구현 방법은 https://github.com/iljoong/facetag에 공유한 소스코드를 참조하시기 바랍니다.
Comparison
Azure Cognitive Service 중에 Custom Vision가 있습니다. 사용자 데이터셋을 기반한 이미지 인식 서비스로 제품의 완성도와 사용 편의성이 매우 높은 것이 장점이며 학습시간이 매우 빠르고 정확도도 높은 편입니다.
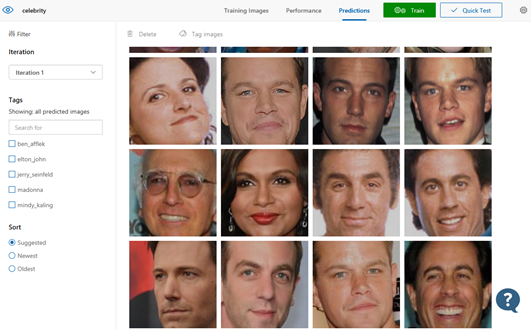
아래는 Custom Vision API를 활용하여 본 서비스에서 얼굴을 식별하는 코드 예 입니다.
#appface.py
def classifyFaceCV(model, frame):
_, roi = cv2.imencode('.png', img)
apiurl = 'https://southcentralus.api.cognitive.microsoft.com/customvision/v2.0/Prediction/%s/image?iterationId=%s'
headers = {"Content-Type": "application/octet-stream", "Prediction-Key": appconfig.api_key }
r = requests.post(apiurl % (appconfig.api_id, appconfig.api_iter), headers=headers, data=roi.tostring())
if (r.status_code == 200):
# JSON parse
pred = json.loads(r.content.decode("utf-8"))
conf = float(pred['predictions'][0]['probability'])
label = pred['predictions'][0]['tagName']
return label, conf*100
else:
return "none", 0.0
Custom Vision API는 아쉽게도 현재 가용 지역이 Southcentral US만 제공되어 한국 사용자의 경우 API의 latency 또는 응답시간이 길고(1 ~ 1.2 초)) 사용 편의성을 너무(?) 강조한 나머지 학습을 커스터마징할 수 있는 방법이 없습니다. 예를 들어, Data Augmentation과 같은 기법을 추가할 수 없습니다.
참고로, 직접 구현한 본 모델의 경우 식별 속도는 D2v3(2 cores)에서 ~0.8초, D4v3는 ~0.4초, D8v3는 ~0.2초가 소요되었고 NC6(K80)에서는 0.03초가 소요되었습니다. D16v3는 D8v3와 유사한 ~0.2초로 약간의 성능향상만 보여줬습니다. 식별만 비교할 경우, GPU VM의 Price-Performance Ratio가 약 3배 정도 좋았고, Latency(한국 위치)까지 고려했을 때 가장 Price-Performance가 좋은 VM은 D8v3 이었습니다. GPU VM이 한국리전에 제공되기 전까지는 D8v3가 좀더 좋다고 할 수 있겠습니다.
그리고, 제가 사용한 테스트 샘플 이미지로만 비교했을 때 직접 구현한 모델은 91%(10/11)의 정확도를 보인 반면 Custom Vision은 73%(8/11)정확도를 보여 데이터셋이 충분하지 않아 overfitting 발생하는 것으로 추정합니다.
Closing
Face Tagging 서비스를 통해 AI 애플리케이션을 개발하는 방법과 지속적인 학습을 지원하는 방법에 대해서 소개했습니다. 본 애플리케이션을 응용하여 요즘 유행하는 이미지 기반 제품 검색서비스와 같은 다양한 AI 기반 비전 서비스를 만들어 보시기 바랍니다.
//iljoong