 Iljoong's Blog
Iljoong's BlogImplementing BCDR on Azure
updated: 2017-05-11
Why BCDR on Public Cloud
퍼블릭 클라우드를 사용하면 장애 걱정도 없고 BCDR(Buisness Continouity & Disaster Recovery)도 필요 없다고 오해하는 분들을 볼 경우가 종종 있습니다. 퍼블릭 클라우드의 데이터센터도 따지고 보면 일반 기업의 데이터센터와 사실 크게 다르지 않습니다. 동일한 HW/SW 기술스택을 사용하고 있고, 단지 차이라면 다양한 경험의 노하우와 높은 자동화 정도 일 것입니다.
가장 안정적이라고 믿고 있던 AWS도 최근 큰 장애가 발생했습니다. 많은 온라인 기업들이 이 장애로 인해 서비스가 접속이 되지 않는 상태가 꽤 오랜 시간 지속되었으나, Amazon과 Netflix는 이 장애와 무관하게 서비스가 원할 하게 제공되었다고 합니다.
Amazon과 Netflix는 그럼 어떻게 서비스를 원할 하게 제공할 수 있었을까요? Amazon은 잘 모르지만 Netflix는 자사의 서비스에 대해서 고가용 아키텍처 및 멀티 리전 운영뿐만 아니라 다양한 테스트(Chaos Monkey, Chaos Gorilla, Chaos Kong)를 통해 언제 어디서, 혹시 발생할 수 있는 장애에 항상 대비하고 있습니다. Netflix의 아키텍처는 Slideshare 등 에서 쉽게 확인할 수 있습니다.
대부분의 기업들은 BCDR을 초기에는 고려를 하지만 운영비용 또는 어떻게 구축을 해야하는 몰라서 제외하는 경우를 많이 보았습니다. 아직도 퍼블릭 클라우드를 사용하는 많은 기업들은 BCDR을 하지않고 있다는 것이 이번 장애로 다시 한번 확인 되었다고 할 수 있겠습니다.
BCDR on Azure
이번에는 비용효과적인 BCDR을 구축하는 방법에 대해서 소개하고자 합니다. BCDR을 위해서는 아래와 같이 동일한 서비스를 멀티 리전에 배포하는 것 입니다.

그리고, 아키텍처 문서에 주요 가용성 고려사항이 자세히 설명되어 있으니 참고하시기 바랍니다. https://docs.microsoft.com/en-us/azure/architecture/reference-architectures/managed-web-app/multi-region-web-app
본 소개에서는 아키텍처 문서에 소개된 고려사항 들을 적용하는, 즉 Traffic Manager, Azure Storage의 RA-GRS를 활용한 BCDR을 구성하는 방법을 소개하겠습니다.
실질적인 소개를 위해서 간단한 웹사이트가 아닌 좀더 현실적인, 복잡한 구성의 데모 서비스(앱)을 사용했습니다. 데모 서비스는 포토 갤러리앱으로, 기본적인 기능(업로드, 썸네일 생성 등)에 추가적으로 인텔리전스 기능인 이미지 캡션(설명)을 추가하였습니다. 서비스 특성을 고려하여 SQL Database 대신 검색에 좀더 특화된 Azure Search를 활용하였습니다. (참고로, Azure Search로 페이징과 Facet을 손쉽게 구현할 수 있습니다.)
전체적인 서비스 아키텍처는 아래와 같습니다.
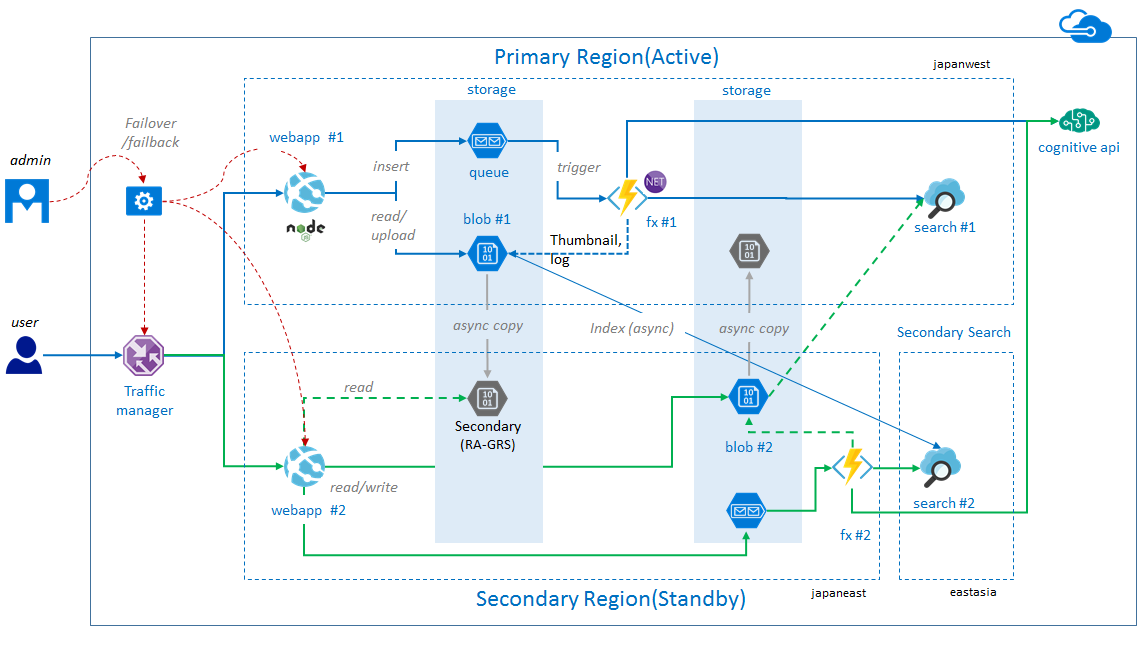
참고로, Azure Search가 모든 리전에 제공되지 않기 때문에, Secondary Search 서비스는 paired 리전이 아닌 가장 가까운 다른 리전에 배치하도록 구성해야 합니다.
각 구성에 대해서 상세하게 알아 보기 전에 먼저 DR 전략에 대해서 알아보도록 하겠습니다.
DR Strategy
DR 구축에 앞서 먼저 DR 전략을 고민해야 합니다. 다시 말하면, RPO(Recovery Point Object)와 RTO(Recovery Time Object)를 어떻게 설정하느냐에 따라 구축 비용과 복잡성에 달라지게 되기 때문입니다. 낮은 RPO와 RTO가 좋지만 이를 위해서는 높은 비용과 복잡한 서비스 구성이 요구될 수 있기 때문입니다. 예를 들어, Active/Active 리전 구성이 RPO/RTO 관점에서는 가장 좋지만, Stateful한 서비스(예: database)를 실시간으로 동기화(sync)하는 것이 어렵고, 또한 failover 및 failback의 구현도 쉽지 않습니다.
본 데모 서비스의 DR 전략은 Active/Active 리전이 아닌 Active/Standby 리전으로 구성하였으며, DR 순서는 다음과 같습니다.
- Primary에 장애가 발생할 경우, Secondary는 Read-only로 먼저 서비스를 제공
- Primary의 장애가 지속될 경우, Admin이 매뉴얼로 Failover을 수행
- Primary가 Active에서 Standby로 Secondary가 Standby에서 Active로 전환
- Admin은 Failback을 수행할 수 있으며, Active/Standby는 Failover의 반대로 전환
다양한 DR 구성 방법은 SQL Database의 DR architecture를 참고하시기 바랍니다.
DR Implementation
BCDR 구축을 위해서 각각의 Azure 서비스 컴포넌트를 구현한 방법에 대해서 자세히 설명합니다.
Traffic Manager
Traffic Manager는 DNS 기반의 로드밸런스로 두 리전의 사이트(특정 URL)를 주기적으로 헬스 체크를 합니다. 아래와 같이 Endpoint 정책은 Priority로 설정합니다.

DNS 쿼리는 우선적으로 Primary 사이트의 주소로 리턴되지만, Primary 사이트의 장애를 감지하면 우선순위에 따라 Secondary 사이트의 주소로 리턴됩니다. 관리자에 의해 Failover를 실행하면 Endpoint의 Priority를 수정되고, 이후부터는 장애여부와 상관 없이 Secondary 사이트가 우선 리턴됩니다.
Webapp
Traffic Manager는 헬스 체크를 위해서 Webapp의 특정 URL(/ping)을 호출하고 HTTP 200 응답을 정상으로 인식합니다. Webapp은 내부적으로 Blob 스토리지와 Search를 호출하여 전체 서비스의 헬스를 체크합니다.
Webapp은 별도의 Primary/Secondary 버전으로 개발되지 않고, 아래와 같이 앱의 환경 변수(예: FOTOS_ISSECONDARY, FOTOS_READONLY)로 인식하도록 개발되었습니다.
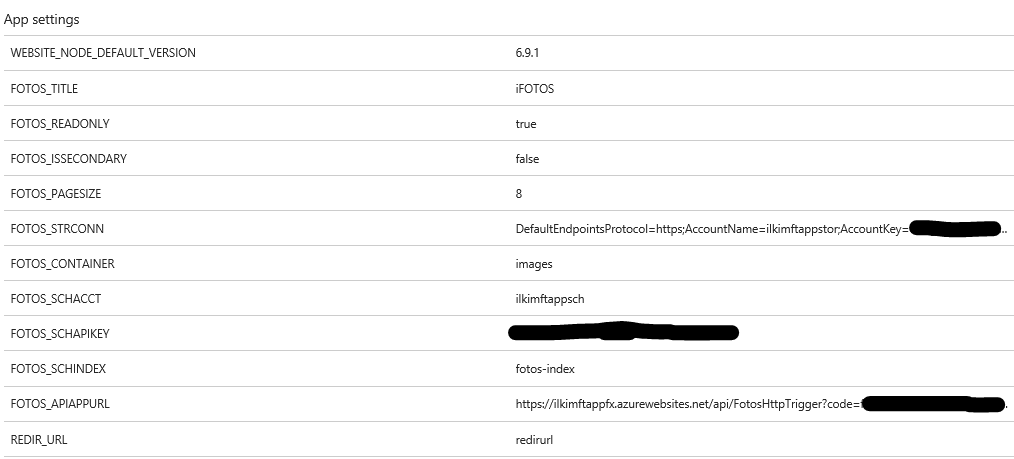
Secodary Webapp은 Secondary 리전의 리소스를 사용하고, 사이트는 아래와 같이 READONLY로만 서비스되어 브라우징, 검색은 되지만 업로드 및 수정은 안됩니다.

Storage
BCDR을 위해서 blob 스토리지는 생성시 RA-GRS 옵션으로 생성합니다. Blob에 저장된 이미지는 자동으로 secondary blob 스토리지에 최대 15분내에 동기화되며, <blobname>-secondary.blob.core.windows.net으로 Read-only로 접근 가능합니다.
참고로, blob 스토리지의 헬스를 확인하기 위해서 health.json이라는 파일하나를 추가하고 주기적으로 호출하여 헬스를 체크합니다.
Functions
이미지는 blob 스토리지에 정상 업로드 후, 비동기적으로 여러 작업 수행할 수 있도록 큐에 작업을 추가 합니다. Azure Functions은 큐에 쌓인 작업을 읽어(또는 트리거되어) 썸네일, 캡션, 검색 인덱스 추가 및 인덱스 로그를 저장합니다.
Search
검색 인덱스(원본 이미지 및 썸네일 이미지 URL, 캡션 및 태그)는 Primary Search에 저장됩니다. 하지만, Secondary Search는 Blob 서비스와 달리 자동으로 복사가 되지 않기 때문에 추가적인 작업 요구됩니다. 앞서 Functions을 통해 생성된 log를 이용하여 Secondary search에 인덱스를 동기화 합니다. 이를 위해서 Secondary search에 primary blob 스토리지를 연결하는 datasource와 indexer를 생성하고 주기적으로 (예: 15분) blob 스토리지의 추가된 로그정보를 접근하여 동기화 합니다.
Failover & Failback
Primary 사이트에 장애가 발생되면 TM에 의해 자동으로 Failover가 되지만 Secondary 사이트는 일단 Read-only로 동작합니다. 관리자는 Primary와 Secondary를 변경하는 failover는 수동으로 할 수 있습니다. 먼저, 아직 동기화되지 않은 Primary Search의 index log에 대해서 동기화를 수행합니다. 그리고, TM의 primary/secondary의 endpoint priority를 변경하고, Primary webapp의 FOTOS_READONLY 환경변수를 "true"로 Secondary webapp의 FOTOS_READONLY를 "false"로 변경하는 작업을 수행합니다. Failover가 이뤄지면, Secondary 사이트는 이제 업로드 및 수정이 가능해지며 실질적인 Primary 사이트의 역할을 수행합니다.
Failback은 앞의 과정을 반대로 수행합니다.
Automation
Failover/Failback 작업을 수작업으로 할 수도 있으나, 스크립트를 이용하여 자동화할 수 있습니다. 아래는 azure-cli를 이용하여 구성한 failover/failback 스크립트 입니다. 참고로, Search는 아직 azure-cli를 제공하지 않기 때문에 REST API 방식을 사용합니다.
#!/bin/bash
if [ $# -eq 0 ]
then
echo "%0 [failover | failback ]"
else
if [ $1 == "failover" ]
then
echo "executing failover"
curl -H "api-key: <apikey>" -H "Content-Type: application/json" -v \
-X post https://<schname>.search.windows.net/indexers/fotos-json-indexer/run?api-version=2016-09-01
az resource update -g <rgname> --namespace "Microsoft.Network/trafficManagerProfiles" \
--resource-type "azureEndpoints" --api-version 2015-04-28-preview \
--parent <tm name> -n <endpoint name> \
--set properties.priority=3 --verbose
az appservice web config appsettings update -n <primary appname> -g <rgname> --settings FOTOS_READONLY=true
az appservice web config appsettings update -n <secondary appname> -g <rgname-dr> --settings FOTOS_READONLY=false
else
echo "executing failback"
curl -H "api-key: <apikeydr>" -H "Content-Type: application/json" -v \
-X post https://<schnamedr>.search.windows.net/indexers/fotos-json-indexer/run?api-version=2016-09-01
az resource update -g <rgname> --namespace "Microsoft.Network/trafficManagerProfiles" \
--resource-type "azureEndpoints" --api-version 2015-04-28-preview \
--parent <tm name> -n <endpoint name> \
--set properties.priority=1 --verbose
az appservice web config appsettings update -n <primary appname> -g <rgname> --settings FOTOS_READONLY=false
az appservice web config appsettings update -n <secondary appname> -g <rgname-dr> --settings FOTOS_READONLY=true
fi
fi
아쉽게도, traffic-manager 설정 변경은 azure cli에 버그가 있어서, 간단한 커맨드가 있으나, workaround로 az resource update 커맨드를 사용했습니다.
https://github.com/Azure/azure-cli/issues/2839
update: azure-cli 버그는 곧 수정될 예정이고, 아래와 같이 사용하면 됩니다.
az network traffic-manager endpoint update -g <rgname> --profile-name <tm name> --name <enpoint name> --priority 3 --type "azureEndpoints"
Demo
아래는 장애 발생시 DR 사이트로 전환되고, failover 및 failback이 수행되는 데모를 캡쳐한 동영상입니다.
장애가 TM에 의해 감지되고 Failover가 적용된다고 해도, DNS의 쿼리만 변경되는 것이기 때문에 실제 사용자에게 적용되는 시점은 DNS 및 브라우저의 캐쉬의 TTL 이후 입니다. 이는 최소 약 2분 30초 소요(TM의 장애 인식 2분, DNS TTL 30초)될 수 있습니다. 자세한 내용은 TM Endpoint 모니터링 참조하세요
DNS 캐쉬를 삭제하는 방법은 CMD 창을 열고 아래의 커맨드를 실행 합니다.
> ipconfig /flushdns
또한, Chrome 웹브라우저는 별도의 캐쉬를 가지고 있어, chrome://net-internals/#dns로 이동하여 삭제해야 합니다.
Conclusion…
데모 서비스를 통해서 Azure의 BCDR를 구축하는 방법을 소개했습니다. 다음에는 본 데모 서비스와 같은 복잡한 구성의 PaaS 서비스 생성을 자동화하는 방법에 대해서 소개하도록 하겠습니다.
그리고, 샘플 앱소스는 github에서 확인 하시기 바랍니다.
/iljoong/