 Iljoong's Blog
Iljoong's BlogScaling AI: Distributed Training
Why Distributed Training is Matter
간단한 AI 학습이 아닌 실제 AI 학습은 대량의 데이터셋이 사용되고 몇 일의 학습 시간이 요구됩니다. AI 학습에는 최신 GPU 카드 및 멀티 GPU가 장착된 서버(노드)를 사용한다고 해도 Scale-up 방식에는 한계가 있으며, Scale-out 방식의 멀티 서버/노드를 활용한 분산학습을 많이 활용합니다.
예를 들어 ImageNet-1K 데이터셋을 8개의 P100 GPU가 장착된 싱글 노드에서 실행할 경우 90 epoch (20% 오류)까지 필요한 학습 시간이 약 1.5일 소요된다고 합니다. Facebook에서는 분산학습을 이용하여 32대의 8xP100 GPU 노드로 학습시간을 1시간으로 줄였다고 합니다. 자세한 내용은 Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour 참조하시기 바랍니다.
학습뿐만 아니라 AI 추론 영역에서도 “batch scoring”과 같이 병렬로 처리하여 작업 시간을 대폭 줄일 수 있습니다. 예를 들어 동영상의 각 프레임을 병렬로 빠르게 추론하는 배치 작업을 수행할 수 있습니다.
클라우드 환경에서는 온프레미스와 달리 필요한 만큼의 자원을 언제든지 손쉽게 사용할 수 있습니다. 싱글 노드로 실행하나 여러 노드를 사용하나 비용적인 큰 차이 없이 학습 시간을 대폭 절약할 수 있는 큰 장점이 있습니다. 물론 노드가 많아질수록 Inter-communication의 증가 등으로 scaling efficiency이 낮아져 실제 학습시간이 늘어나며 비용은 어느 정도 상승합니다.
이번 블로그에서는 Azure에서 AI 분산학습을 위한 방법에 대해서 소개하겠습니다.
First Distributed Trainning
Horovod
AI 분산학습은 AI 프레임워크 별 여러 Toolkit/API가 있었으나 최근에는, 특히 Tensorflow/Keras AI 프레임워크에서는, Uber에서 오픈소스로 공개한 Horvod가 많이 활용되고 있습니다. Horovod는 기존 Tensorflow에서 사용되는 parameter 서버 방식보다 보다 효율적인 분산학습을 제공한다고 합니다.
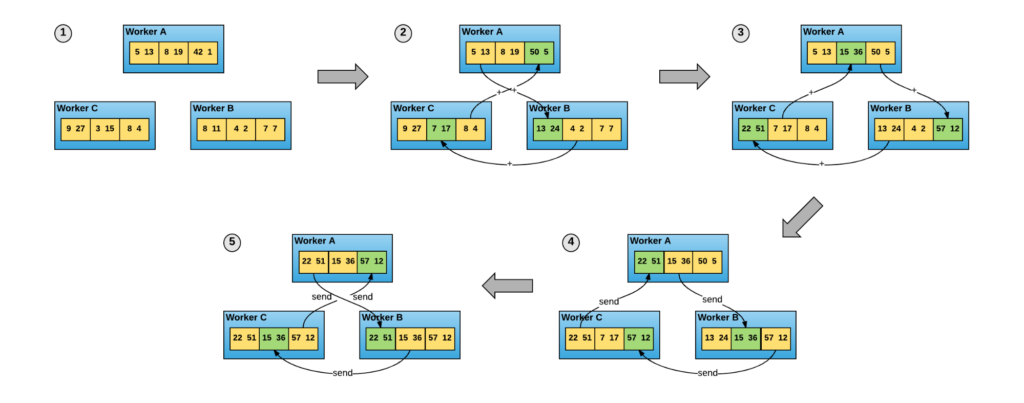
Uber는 HPC에서 사용되는 MPI 방식에서 영감을 얻었다고 하며 자사의 AI 분산학습을 위해서 기존 중앙화된 parameter 서버방식이 아닌 링구조로 노드가 메시징을 주고받은 allreduce 방식을 사용했다고 합니다.
Runnig Horovod with Azure DSVM
AI 분산학습을 Horovod로 Azure에서 테스트하기 위해서 먼저 다음과 같은 환경을 구성합니다.
- VM 구성: Azure DSVM (Ubuntu 16.04) 이미지로 2대 이상의 NC6v1 또는 NC12v1 VM 생성
- 테스트 데이터셋: Tensorflow Benchmark의 Synthetic data를 사용
Tensorflow Benchmark는 최신
master가 아닌cnn_tf_v1.10_compatiblebranch가 사용될 수 있도록 설정
분산학습을 실행할 VM으로 Azure의 DSVM를 사용한 이유는 분산학습에 필요한 SW (MPI) 및 패키지(tensorflow, horovod)가 이미 설치되어 있기 때문이고, 테스트 데이터셋으로 Tensorfow benchmark(synthetic)를 사용하는 이유는 구성이 간단하고 또한 다양한 GPU/노드 구성의 성능비교에 용이하기 때문입니다.
분산학습 실행은 mpirun 커맨드를 사용하며 실행 위치는 테스트 VM(예: 10.4.0.4)에서 실행합니다. 아래는 2대의 노드에 각 GPU 한 개씩 실행하는 예입니다.
mpirun -np 2 \
-H 10.4.0.4,10.4.0.5 \
-bind-to none -map-by slot \
-x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH \
-mca pml ob1 -mca btl ^openib \
-mca btl_tcp_if_exclude lo,docker0 \
\
python ~/benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py \
--model resnet50 \
--batch_size 64 \
--variable_update horovod
처음 실행 시 start-up 시간이 많이 소요되므로 충분히 기다릴 것
Horovod 실행을 위한 자세한 방법은 Horovod 문서를 참조하시기 바랍니다.
Issues on DSVM
Azure DSVM에서 horovod의 문서대로 실행할 경우 2가지 실행 이슈가 발생합니다.
- openmpi version:
hostname:<n> is not recognizing- DSVM에 기본으로 설치된 mpi 버전이 1.10.2라서 process/gpu 수를 지정하는 패러미터를 인식하지 못해 3.x로 업그레이드 필요
- 1.10에서는 process/gpu를 지정하는 대신 hostname을 process/gpu 수만큼 지정하여 사용 가능 (예: 10.4.0.4:2 -> 10.4.0.4,10.4.0.4)
- network interface (docker)
- DSVM은 docker가 설치되어 있어
docker0,lo네트워크 인터페이스의 라우팅 문제로 실행 중지 발생 mpirun커맨드에-mca btl_tcp_if_exclude lo,docker0패러미터 추가
- DSVM은 docker가 설치되어 있어
추가적으로 MPI가 정상적으로 실행될 수 있도록 미리 VM에 SSH로 미리 로그인 실행
Running on Azure BatchAI
앞서 AI 분산학습을 위해서 Horvod를 일반적인 IaaS 환경에서 사용하는 방법을 설명했습니다. 하지만 이 방법은 다수의 노드를 구성 및 설정하고 반복적인 실험/작업 결과를 관리하는 것은 귀찮을 수 있고, 항상 학습을 수행하는 것이 아니기 때문에 종종 VM을 중지시키거나 해야 하는 수고가 요구됩니다. Azure에서는 이런 반복 주기적인 배치 작업을 좀더 편리하게 수행할 수 있는 BatchAI 서비스를 제공하며 horovod를 포함한 다양한 AI Toolkit들의 분산학습 방법을 지원하고 있습니다.
BatchAI는 실제 사용되는 VM의 비용을 제외하고는 서비스 비용은 없으며 또한 일반 VM뿐만 아니라 20% 가격으로 할인된 LPVM(Low Priority VM)을 사용할 수 있어 또한 경제적입니다. 물론, LPVM을 사용하면 VM이 언제든지 회수되기 때문에 학습이 중간에 중단될 수도 있으나 대부분의 AI 프레임워크들은 checkpoint를 제공하여 중단 이후에도 마지막 checkpoint부터 학습을 시작할 수 있어 충분히 고려해볼 만합니다.
앞서 테스트한 AI 분산학습과 동일한 테스트를 BatchAI로 수행하는 기본적인 가이드는 링크를 참조하시기 바라며, 몇 가지 차이점 및 주의할 부분을 추가적으로 설명합니다.
앞선 학습방법과 달리 BatchAI에서는 먼저 배치 또는 학습 작업(job)을 수행하기 위한 구성을 미리 수행해야 합니다.
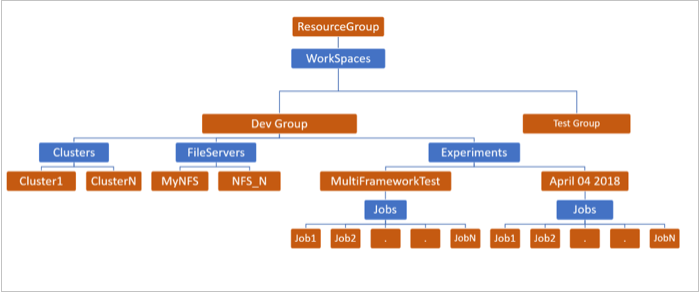
- BatchAI 서비스 생성 및 워크스페이스 생성
- BatchAI에서 분산학습에 사용할 VM 클러스터 생성
az batchai cluster create --name <cluster> --workspace <workspace> --resource-group batch-rg \
--vm-size STANDARD_NC12 --image UbuntuLTS --min 2 --max 2 \
--afs-name batchshare --afs-mount-path azurefileshare \
--storage-account-name <azfile> \
--storage-account-key $AZURE_STORAGE_KEY \
--vm-priority lowpriority \
-u aiuser -k ~/.ssh/id_rsa.pub
- 공유 파일 서버 (Azure Files, NFS, Blobfuse)를 구성
- tensorflow bechmark repo를 Azure Files로 구성한 공유 폴더에 복사
- 배치로 실행할 실험(experiment) 생성
BatchAI의 구조는 링크를 참조하시기 바랍니다.
job.json
BatchAI가 구성되었으며 JSON형태의 job 파일을 아래와 같이 생성합니다. 참고로, job.json 파일은 배치에 사용될 노드/GPU 수, 공유 서버의 볼륨 마운트 위치, 컨테이너 이미지 및 준비작업(설치 등)을 지정합니다.
{
"$schema": "https://raw.githubusercontent.com/Azure/BatchAI/master/schemas/2018-05-01/job.json",
"properties": {
"nodeCount": 2,
"horovodSettings": {
"pythonScriptFilePath": "$AZ_BATCHAI_JOB_MOUNT_ROOT/batchshare/benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py",
"commandLineArgs": "--model resnet50 --batch_size 64 --variable_update horovod",
"processCount": 4
},
"stdOutErrPathPrefix": "$AZ_BATCHAI_JOB_MOUNT_ROOT/logs",
"mountVolumes": {
"azureFileShares": [
{
"azureFileUrl": "https://batchaishare.file.core.windows.net/batchshare/logs",
"relativeMountPath": "logs"
},
{
"azureFileUrl": "https://batchaishare.file.core.windows.net/batchshare",
"relativeMountPath": "batchshare"
}
]
},
"jobPreparation": {
"commandLine": "apt update; apt install mpi-default-dev mpi-default-bin -y; pip install torch; pip install horovod"
},
"containerSettings": {
"imageSourceRegistry": {
"image": "tensorflow/tensorflow:1.10.1-gpu"
}
}
}
}
properties/nodeCount는 VM의 노드 수이며,properties/horovodSettings/processCount는 프로세스/GPU 수로 2대의 NC16v에서 실행시nodeCount는 2로processCount는 4로 지정. 참고로,processCount는 기본 값으로nodeCount값으로 지정
Azure 문서에는 누락되어 있는데 jobPreparation 항목에서 Python torch 패키지를 horovod 패키지 전에 설치해야 합니다.
참고로 $AZ_BATCHAI_JOB_MOUNT_ROOT 환경변수는 /mnt/batch/tasks/shared/LS_root/jobs/<workspace>/<exp>/<jobn>/mounts로 매핑됩니다.
배치 작업을 컨테이너로 실행되며 external storage는 컨테이너 내의 /mnt/batch/tasks/shared/LS_root/mounts 마운트됩니다. Azure Files와 같은 external storage가 아닌 local storage를 사용할 경우에는 해당 VM의 /mnt/batch/tasks/shared/LS_root/mounts 하위에 파일을 복사하고 job.json은 아래와 같이 수정합니다.
"pythonScriptFilePath": "/mnt/batch/tasks/shared/LS_root/mounts/benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py",
Run BatchAI
Azure CLI로 분산학습 Job을 실행합니다.
az batchai job create --resource-group batch-rg --name job01 \
--workspace <workspace> --cluster <cluster> --experiment <experiment> \
--config-file job.json
배치 작업이 실행되면 실행 log, stdout 및 stderr 출력이 지정한 파일서버에 기록되며 파일서버 또는 포탈을 통해서 확인이 가능하며, 스트림으로 진행 결과, 실행 오류를 확인할 수도 있습니다. 배치 작업이 완료되면 실행 결과를 파일 서버에서 다운로드 받을 수 있습니다.
GPU Monitoring
BatchAI는 테스트를 진행하면서 정상적인 성능이 나오지 않은 경우가 있었습니다. CPU 및 메모리의 상태는 확인 가능하지만, 성능에 가장 중요한 GPU 관련 성능 metric은 기본적으로 확인이 불가능합니다. 학습 시 GPU를 손쉽게 모니터링할 수 있는 오픈소스 https://github.com/msalvaris/gpu_monitor.git가 있어 추천합니다.

상세한 사용 방법은 README을 참고하시기 바라며, tensorflow benchmark에서는 tf_cnn_benchmarks.py를 아래와 같이 수정하여 tf_cnn_benchmarks_gpumon.py 으로 저장합니다.
import socket
from gpumon.influxdb import log_context
LOGGER_URL='<influxdb_hostip>'
LOGGER_USRENAME='admin'
LOGGER_PASSWORD='password'
LOGGER_DB='gpudb'
LOGGER_SERIES='gpuseries'
LOGGER_VM=socket.gethostbyname( socket.gethostname() )
...
bench.print_info()
with log_context(LOGGER_URL, LOGGER_USRENAME, LOGGER_PASSWORD, LOGGER_DB, LOGGER_SERIES, machine=LOGGER_VM):
bench.run()
그리고, job.json 파일은 아래와 내용을 반영하여 job-gpumon.json으로 저장하고 실행합니다.
"nodeCount": 2,
"horovodSettings": {
"pythonScriptFilePath": "$AZ_BATCHAI_JOB_MOUNT_ROOT/batchshare/benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks_gpumon.py",
"commandLineArgs": "--model resnet50 --batch_size 64 --variable_update horovod",
"processCount": 4
},
...
"jobPreparation": {
"commandLine": "apt update; apt install mpi-default-dev mpi-default-bin git pandoc -y; pip install torch; pip install horovod; git clone https://github.com/msalvaris/gpu_monitor.git; pip install -r gpu_monitor/requirements.txt; pip install -e gpu_monitor"
},
gpumon 은 python 2.7에서는 정상적으로 실행이 되지 않음. 기본
tensorflow/tensorflow:1.10.1-gpu컨테이너 이미지는 python 2.7을 사용하여 실행이 안됨
추가로, GPU 모니터링 정보를 수집 및 대시보드로 보기위해서는 influxdb와 grafana가 추가 설치되어야 합니다. gpu_monitor/scripts/ 폴더에 docker-compose로 손쉽게 배포할 수 있게 패키징되어 있어 docker 엔진이 설치된 VM을 생성하여 구성합니다.
Distributed Training Result
각 구성별 Tensorflow benchmarking (ResNet-50)의 결과는 다음과 같습니다.
| test | node | gpu | images/sec | images/sec/gpu | note |
|---|---|---|---|---|---|
| 1 | 1 | 1 | 56.57 | 56.57 | DSVM (python3) + local |
| 2 | 1 | 2 | 109.34 | 54.67 | DSVM (python3) + local |
| 3 | 2 | 1 | 109.72 | 54.86 | DSVM (python3) + local |
| 4 | 2 | 2 | 209.87 | 52.47 | DSVM (python3) + local |
| 5 | 2 | 1 | 106.38 | 53.19 | BatchAI (tensorflow/tensorflow:latest-gpu-py3)/lowpriority + azure files |
| 6 | 2 | 2 | 205.18 | 51.30 | BatchAI (tensorflow/tensorflow:latest-gpu-py3)/lowpriority + azure files |
| 7 | 2 | 2 | 211.02 | 52.76 | BatchAI (tensorflow/tensorflow:latest-gpu-py3)/dedicated + azure files |
테스트 실행 상황 (warm-up 상태, GPU 온도, 네트워크)에 따라 실제 benchmark의 결과는 다소 차이가 있을 수 있음
Horovod의 benchmark 문서에 의하면 ResNet-101의 Scaling efficiency가 90% 정도 가능하다고 합니다. 본 테스트에서 환경에서 4개의 GPU를 사용한 구성에서 이론적으로 54.99 x 4 = 226.28 images/sec의 성능이 예상되지만 실험 #6의 경우 205.18 images/sec 성능(91% scaling efficiency)이 기록되었습니다.
DSVM과 달리 BatchAI에서는 컨테이너로 실행되지만 성능의 큰 영향을 주지 않는 것 같습니다. 컨테이너로 실행되기 때문에 매번 준비 작업을 수행하여 시간이 다소 소요되는데 커스텀 이미지를 만들어 시간을 줄일 수도 있습니다. 컨테이너의 영향은 없지만 Azure BatchAI의 Low Priority_와 _Dedicated VM 옵션 여부는 차이는 있는 것 같습니다. Low Priority 옵션을 사용할 때 성능이 급격히 다운되는 현상이 가끔씩 발생했습니다.
테스트에 사용한 스크립트와 상세 벤치마킹 결과는 https://github.com/iljoong/aoa-sample/tree/master/horovod를 참조하시기 바랍니다.
Closing
Horovod를 이용한 분산학습을 실행하는 방법에 대해서 알아보았으며, Azure BatchAI를 활용하여 관리적으로 좀더 편리한 실행 방법에 대해서 알아보았습니다. 분산학습의 효율을 위해서는 네트워크 및 스토리지 옵션에 따라 큰 차이가 있을 수 있기 때문에 이 부분도 충분히 고려할 사항입니다. 그리고, 일반적으로 다수의 실험을 분산학습으로 빠르게 처리하는 것 보다는, 병렬로 싱글 GPU에서 실행하는 것을 좀더 효과적이라고 합니다.
마지막으로, Azure BatchAI의 다양한 샘플 recipe를 참조하시기 바랍니다.
//iljoong