 Iljoong's Blog
Iljoong's BlogAI on Azure: Deep Learning Basics
AI의 기본이 되는 Deep Learning 의 이론적인 부분을 용어 위주로 간단하게 다루고자 합니다. 자세한 내용은 서적 또는 검색을 통해 관련 정보를 참고하시는 것을 권장하며 본 가이드는 처음 용어를 접하는 용도 정도로만 활용하시면 좋을 것 같습니다.
개인적으로 모두가 추천하는 Stanford CS231n 강의를 추천합니다.
- 강의 사이트: http://cs231n.github.io/
- 2017 강의 Youtube 링크: https://www.youtube.com/playlist?list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv
- 2018 강의 노트(PDF): http://cs231n.stanford.edu/slides/2018/
한번에 모두 시청하기도 어렵고 이해하기도 어렵기 때문에 강의를 모두 시청한 후 실습을 하는 것 보다는 시청과 실습을 병행해서 진행하는 것이 좋은 것 같습니다. 실습에서 경험한 오류와 궁금증들이 강의를 시청할 때 좀더 잘 들리는 것 같습니다. 새로운 용어들과 친숙해지는 것 뿐만아니라 주요 용어에 대해서는 정확하게 알고 있어야만 Deep Learning을 제대로 활용할 수 있는 것 같습니다.

Deep Learning의 넓은 범위를 모두 커버를 하지 않으며, 주로 Image Classification의 Convolutional Neural Network 모델을 중심으로만 설명하고자 합니다.
Basic Component
Deep Learning도 Machine Learning(ML)이 한 줄기로 기본 매커니즘은 동일합니다. 즉, x 입력(input), y 출력(output) 그리고 f(x) 함수로 구성되어 있습니다. 보통 입출력은 scalar 값이 아닌 vector 또는 n-dimensional 값이 사용됩니다.
y = f(x)
f(x) = sigmoid ( Wx + b )
함수는 입력(x)과 W(weight)를 곱하고 b(bias)를 합한 값을 sigmod와 같은 활성 함수(Activation function)를 통해 학습이 이뤄졌는지 학습이 이뤄지지 않은지를 결정합니다.
Training Components
학습은 실 출력 값과 기대 출력값을 비교하여 weight와 bias의 패러미터 값을 조정하는 과정입니다. 이런 조정 과정은 ML과 마찬가지로 두 값의 오차를 최소화하는 학습 목표를 가집니다. 오차를 최소화 하기 위해서는 오차를 측정할 수 있는 Cost 또는 Loss을 정의해야 합니다. Loss Function은 학습 종류(regression, binary, categorical)에 따라서 선택합니다. 그리고 각 학습마다 얻은 Loss Function 값의 합을 최소화 시켜주는 (역전달을 통해 기울기를 줄이는) 최적화 알고리즘(Optimizer)을 선정합니다. 최적화 알고리즘으로 SGD(Stochastic Gradient Decendant), RMSProp, Adam과 같은 다양한 알고리즘이 있으며 프레임워크에서 기본으로 제공됩니다.
아래는 최적화 알고리즘별 학습속도를 보여주고 있습니다.
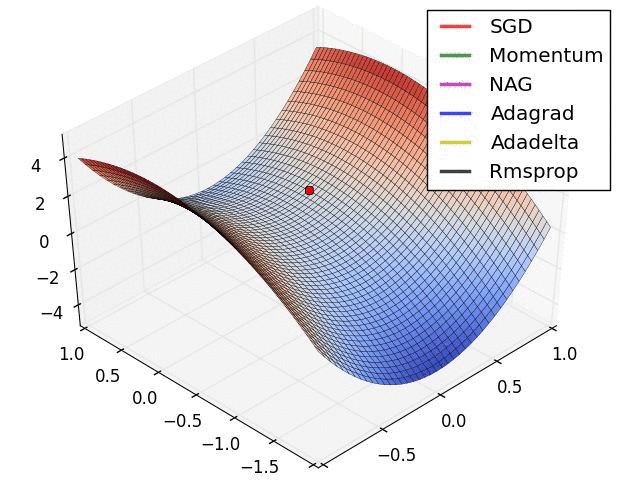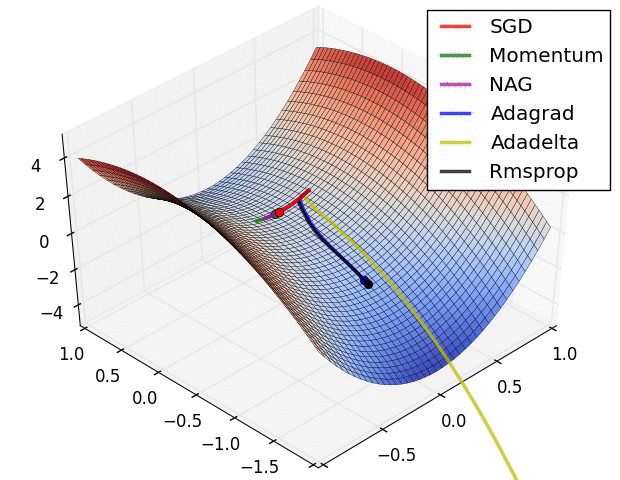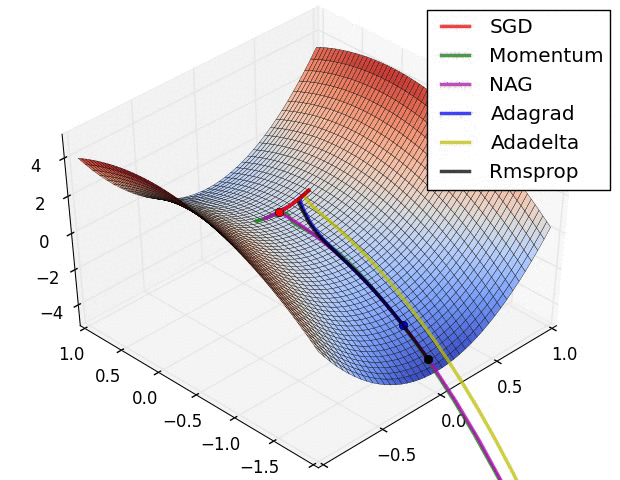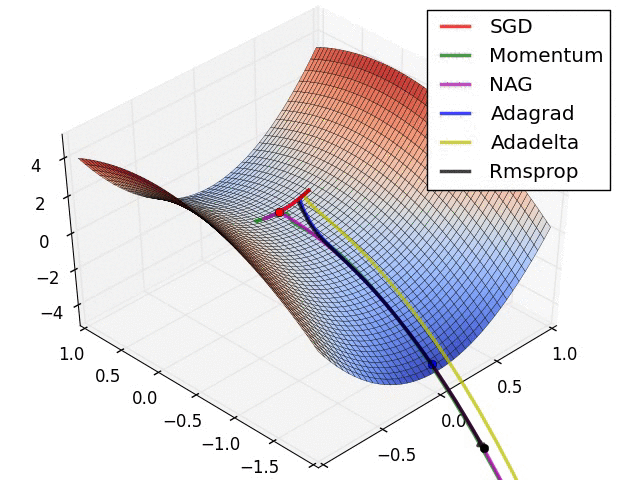
Optimizer와 Loss function과 더불어 학습율(learning rate)과 같은 hyperparameters 중요하며, 학습의 속도 및 수렴의 주요 요소 입니다. 높거나 낮지 않은 적절한 hyperparameters 값을 사용해야만 최적화로 수렴할 수 있습니다. 아래의 그림에서 learning rate의 값에 따른 학습 수렴을 참고하시기 바랍니다.
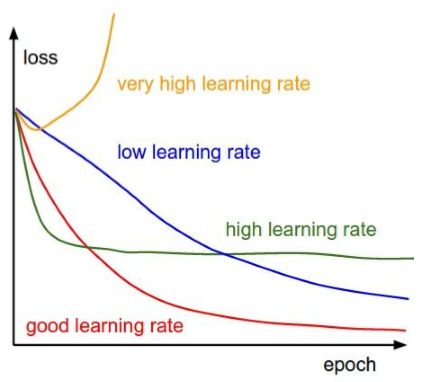
source image from cs231n_2018_lecture06.pdf
학습의 주요 지표로 precision, recall 및 accuracy를 사용합니다. 학습 데이터량이 큰 경우 메모리의 한계로 인해서 한번에 모든 데이터를 학습할 수 없습니다. 한번에 학습할 수 있는 적절한 데이터 크기(batch size 또는 minibatch size)를 선정해서 그만큼만 점진적으로 학습 시킵니다. 데이터셋 모두 학습한 것을 epoch/sweep 이라고 하며, 충분한 지표 결과(accuracy)를 얻을 때까지 반복적으로 여러번 학습을 수행합니다.
Initialization & Regularization
CNN에서는 초기화가 중요하다고 하는데, 일반적인 초기화 알고리즘은 Layer가 깊어질 수록 gradient가 0으로 수렴되어 학습이 전해 이뤄지지 않게 된다고 합니다. 이를 방지하기 위해서 Glorot/Xavier 초기화를 사용한다고 합니다. (Keras의 기본 초기화 함수는 Glorot 임)
학습을 통해 얻은 결과가 학습 데이터에만 너무 최적화되면 실제 데이터에서 제대로 추론이 안되는 경우가 발생할 수 있습니다. 이런 경우를 overfit되었다고 하며 training accuracy 보다는 validation accuracy가 더 중요하게 봅니다. 즉, 아래와 같이 training 및 validation의 차이가 크면 overfit되었다고 이야기 합니다.
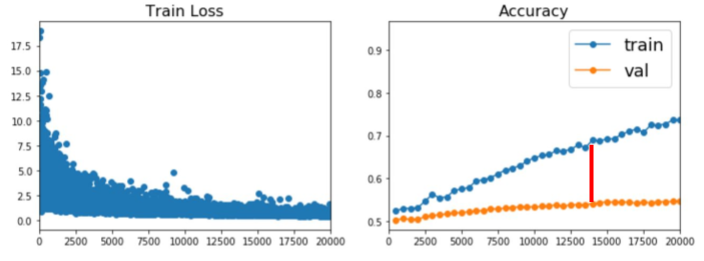
source image from cs231n_2018_lecture07.pdf
overfit을 방지하기 위해서 다양한 regularization 기법을 사용하며, Dropout layer는 regularization 기법 중 하나 입니다. Dropout layer를 추가하여 불필요한 feature를 제거하여 일반화를 좀더 강화할 수 있는데, 쉽게 설명하면 안경이라는 feature를 제거하여 가족의 얼굴 인식을 높일 수 있습니다. (예를 들어 아빠가 안경을 쓴 사람인 경우, 선글라스를 쓰면 무조건 아빠로 인식되는 경우를 방지)
추가적인 Regularlization 기법으로 다음과 같은 기법을 고려할 수 있습니다.
-
Batch Normalization: 입력 데이터를 정규화(normalize)하는 것이 아닌 네트워크내의 입력층(Input Layer)을 정규화하는 방식으로 학습 시의 배치 입력데이터에 대해서 정규화가 수행.
-
Data Augmentation: 학습을 위한 충분한 데이터를 준비하는 것은 어렵기 때문에 Flip, Crop, Zooming과 같은 기법을 이용하여 하나의 입력 데이터를 다수의 입력 데이터로 만드는 방법.
Model & Layers
Deep Learning은 이름에서 유추할 수 있듯이 다수의 Layer들로 구성됩니다. 특히, 대표적인 Convolutional Neural Network(CNN)은 Neural Network(Fully Connected/Dense) layer (2~3 layers)뿐만 아니라 Convolution Layer가 10 여개에서 많게는 100개 이상 사용됩니다.
Convolution layer는 필터링 레이어로 이미지의 주요 feature들을 인식하는 용도라고 이해하면 좋을 것 같습니다. Convolution layer의 구조상 데이터량(이미지 크기 x 채널 x 필터 수)이 매우 크기 때문에 데이터 처리량을 효과적으로 줄여주는(downsizing) 기법으로 pooling layer를 추가합니다. Pooling을 위해서 각 convolution filter를 점진적(stride 크기만큼)으로 이동하여 계산하는데, 데이터 크기 정확하게 일치할 수 있지 않기 때문에 padding을 추가합니다. (Padding 크기도 대부분의 프레임워크가 자동으로 계산)
CNN을 처음 접할 때 가장 어려웠던 컨셉인데, 아래 링크에서 Convolution Layer가 동작하는 애니메이션을 보면 좀더 쉽게 이해가 가능합니다.
http://cs231n.github.io/convolutional-networks/
CNN의 대표적인 구현 모델은 Alexnet 입니다. Alexnet을 이후 Deep Learning이 급격히 성장하고 있으며, 이후 CNN을 바탕한 다양한 모델들이 나오고 있습니다. 잘 알려진 주요 모델의 설명은 본 링크를 참조하시기 바랍니다.
Input Datasets & Output
데이터셋의 입력 값에 대한 고려 사항은 다음과 같습니다.
-
Data Loading: 대량의 학습 데이터를 모두 메모리로 로딩할 수 없고, 반복적으로 접근하기 때문에 좀더 효율적인 방법이 필요. Caffe의 경우 미리 LMDB로 학습데이터를 DB화 하는 방법을 사용하기도 하며, CNTK와 Keras는 데이터를 손쉽게 serialize/deserialize할 수 있는 편리한 별도의 API를 제공.
-
Transformation: 우리가 알고 있는 이미지는 CHW (Channel, Height, Width)로 구성되어 있지만, 효율적인 GPU 계산을 위해서 HWC 포맷으로 변환이 필요. 대부분 프레임워크에서 학습시 알아서 포맷을 변경해 주지만, 추론 시 입력 데이터를 학습에 사용했던 포맷으로 변경.
-
Input Normalization: 이미지의 데이터셋의 경우 가장 간단한게 255 나누는 방법을 사용하기도 하고, 모든 training 데이터셋의 mean 이미지를 생성하여 mean 이미지로 normalization 하는 기법도 사용(학습시에만 사용). 코딩을 필요하지만 Caffe의 경우 별도의 command tool(
caffe/build/tools/compute_image_mean)을 제공. -
Histogram Equalization: Histogram Equalization을 사용하여 이미지를 일반화.
학습 시 사용되는 데이터셋의 출력 값은 OHE(One Hot Encoding)과 같은 포맷이 주로 사용되기도 합니다. 예를 들어 10개의 class가 있는 출력의 값이 3번째 클래스라고 할 때 scalar 값인 2 보다는 vector 값인 [0 0 1 0 0 0 0 0 0 0]를 사용합니다. 마찬가지로 Prediction의 결과 값도 유사한 포맷으로 출력되기 때문에 의미있는 값으로 변환해 주어야 합니다.
pred = model.predict(x)
class = np.argmax(pred)
Transfer Learning
CNN과 같은 모델을 제대로 학습(예: 90% 이상 accuracy) 시키려면 많은 데이터와 시간이 필요합니다. 하지만, Transfer Learning 기법을 사용하면 학습시간을 대폭 줄일 수 있습니다. 이 기법은 간단하게 설명하면 이미 잘 학습된 모델에서 Top layer (Dense layer)만 교체하여 새로 학습시키는 방식입니다.
예를 들어 ImageNet 데이터셋으로 이미 학습된 모델에 Transfer Learning 기법으로 Dogs/Cats을 학습시키면 10 epoch 정도에 97% accuracy를 얻을 수 있습니다. 모델을 처음부터 학습시키는 경우 100 epoch을 넘어야 90% 정도 accuracy를 얻을 수 있습니다. 아래는 VGG16 모델의 Dogs/Cats 이미지 학습 시, learning rate 및 transfer learing 사용 별 train accuracy 입니다.
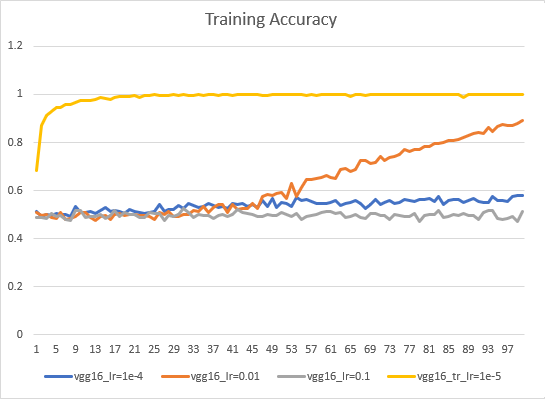
Deep Learning Process
DL은 크게 두가지 파트로 구성됩니다. 하나는 학습(training)이고 하나는 추론(inferencing/prediction)입니다. 학습은 일반적으로 시간이 많이 소요(몇시간~몇일)되고, 배치작업으로 수행됩니다. 추론은 애플리케이션 부분으로 빠른 추론이 요구(ms)됩니다.
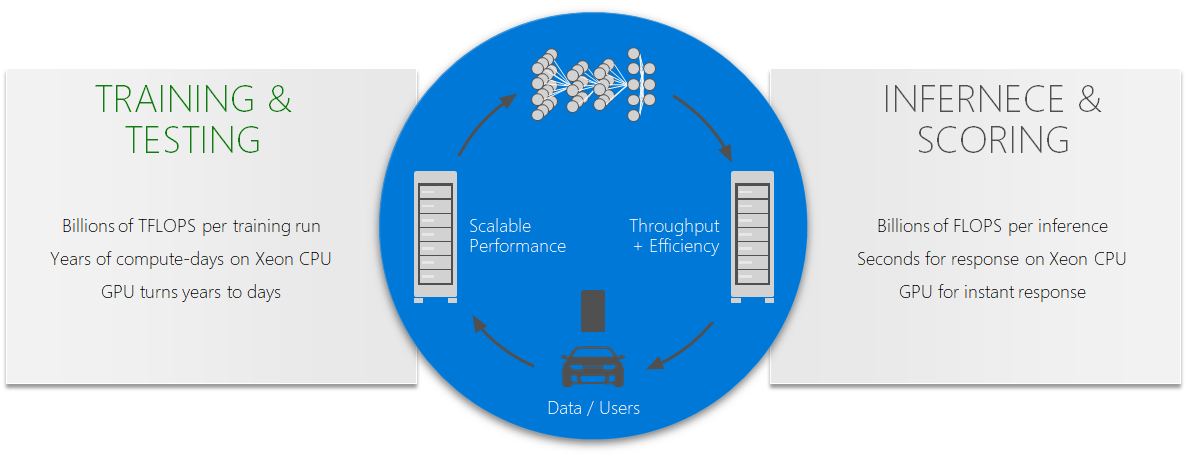
학습과 추론은 일반적으로 GPU VM이 사용되지만, 최근에는 FPGA를 기반한 Project Brainwave와 같은 추론 서비스가 나오고 있습니다. 추론에서는 FPGA가 GPU 대비 보다 효율적이고, 빠른 응답이 가능하다고 합니다. 참고로, 매우 시간적 민감한 앱이 아니라면 추론을 CPU VM에서도 수행할 수 있습니다.
// iljoong